


Amazon OA难度对比:Google vs Meta vs Amazon
Amazon面试题库是否固定?内部规律深度解析
很多人在准备 Amazon 面试时都会问一个核心问题:
“题库是不是固定的?刷旧题有没有用?”
尤其在“amazon ai coding”趋势越来越明显之后,这个问题变得更关键。
答案先说结论:
Amazon面试题库不固定,但高度“结构化重复”
表面是随机题,本质是“题型规律循环 + 变形出题”
下面给你拆开讲清楚真实内部规律。
题库不是固定的,但题型是“半固定结构”
很多人误以为Amazon像考试一样有“题库”,其实完全不是。
Amazon的题目来源通常是三类:
- 历史题目变形(最常见)
- 新题加入旧框架(中等频率)
- 业务抽象题(AI coding越来越多)
所以你会发现:
👉 题目内容在变
👉 但“解法模型”在重复
例如:
- “最长子数组” → 每年换描述
- “任务调度” → 换成物流/云计算背景
- “缓存设计” → 换成推荐系统/日志系统
本质都是同一类算法结构。
Amazon出题的核心规律:不是考题,是考“模型”
Amazon面试最关键的一点是:
不是考你做过什么题,而是考你是否掌握“问题模型”
常见稳定模型包括:
数组 / 字符串模型(最高频)
- 双指针
- 滑动窗口
- 前缀和
- 哈希统计
👉 90%的easy + medium变体都在这里
树 / 图模型(中高频)
- DFS / BFS
- 拓扑排序
- 最短路径简化版
👉 本质是“依赖关系建模”
动态规划模型(中高难)
- 背包变体
- 序列最优解
- 状态压缩
👉 Amazon喜欢“包装成业务问题”
系统模拟模型(AI coding重点)
- LRU Cache
- rate limiter
- task scheduler
- logging / queue system
👉 这是近年来AI coding面试重点增加的部分
“换皮出题”是Amazon最典型风格
Amazon的题目非常典型的一点是:
题目几乎不重复,但“骨架高度重复”
举个真实风格例子:
原始模型:
“找出最长不重复子串”
Amazon可能变成:
“检测用户请求日志中最长无重复访问区间”
或者:
原始模型:
“拓扑排序”
Amazon可能变成:
“计算任务依赖执行顺序”
你会发现:
✔ 输入变了
✔ 业务背景变了
✔ 甚至函数名字都变了
但算法本质没变。
OA / AI Coding阶段 vs 面试阶段:规律不一样
OA(Online Assessment)
特点:
- 更标准化
- 更接近LeetCode
- 更依赖算法正确性
👉 题型重复率较高(但不是固定)
AI Coding / Technical Interview
特点:
- 更开放
- 更工程化
- 更像真实工作
👉 规律变成:
- “系统模块化题”频率上升
- “代码阅读 + 修改题”增加
- “边界与扩展能力”更重要
Amazon真正的“隐藏题库规律”
如果你想理解本质,可以记住这3条:
规律一:题目在变,但考点不变
Amazon不会考“新算法”,只会换包装方式。
👉 核心能力永远是:
- 数据结构选择能力
- 问题建模能力
- 复杂度控制能力
规律二:高频题 ≠ 真实题库
网上所谓“Amazon高频题库”只能覆盖:
- 30%基础题型
- 40%变体结构
- 30%不可预测新题
👉 也就是说刷题能提分,但不能“押中考试”
规律三:面试官有“出题模板库”
虽然不是固定题库,但Amazon内部确实有:
- 标准题模板(cache / graph / DP)
- 可替换业务背景
- 可调难度参数
👉 本质是“工业化出题系统”
为什么很多人觉得“题目越来越随机”?
原因其实有三个:
第一:业务场景包装越来越复杂
AI coding之后,题干变长了
第二:同一算法被多次改写
导致“似曾相识但不会做”
第三:考察重点变成“综合能力”
不再只是算法正确性,还包括:
- 代码结构
- 可读性
- 边界处理
- debug能力
最重要的结论(很多人忽略)
如果你只记住一句话:
Amazon没有固定题库,但有“固定思维结构”
真正决定你能不能过的,不是你刷没刷到原题,而是:
✔ 看到题目能不能快速归类模型
✔ 能不能在45分钟内写出稳定代码
✔ 能不能处理边界 + 扩展需求
如果你想进一步提升
我可以帮你做更实用的版本,比如:
- amazon ai coding
高频“模型题清单” - 真实面试变形题对照表
- 2周/4周冲刺刷题路线
- 或者“看到题就秒分类”的方法训练
只要你说你的当前水平,我可以帮你定制一套更具体的准备策略。
Kategoriler
Read More
The global Children's Cosmetics Market is experiencing significant growth as parents increasingly seek safe, age-appropriate, and high-quality beauty products for their children. Rising awareness regarding ingredient safety, growing demand for natural formulations, and the expansion of online retail channels are transforming the industry landscape. According to M2 Square Consultancy,...
"Executive Summary Bronze Market Size and Share Across Top Segments Data Bridge Market Research analyses that the bronze market is expected to reach USD 13.17 billion by 2030, which is USD 10.08 billion in 2022, registering a CAGR of 3.40% during the forecast period of 2023 to 2030.Market drivers and market restraints covered in this Bronze report give an idea about the rise or fall...
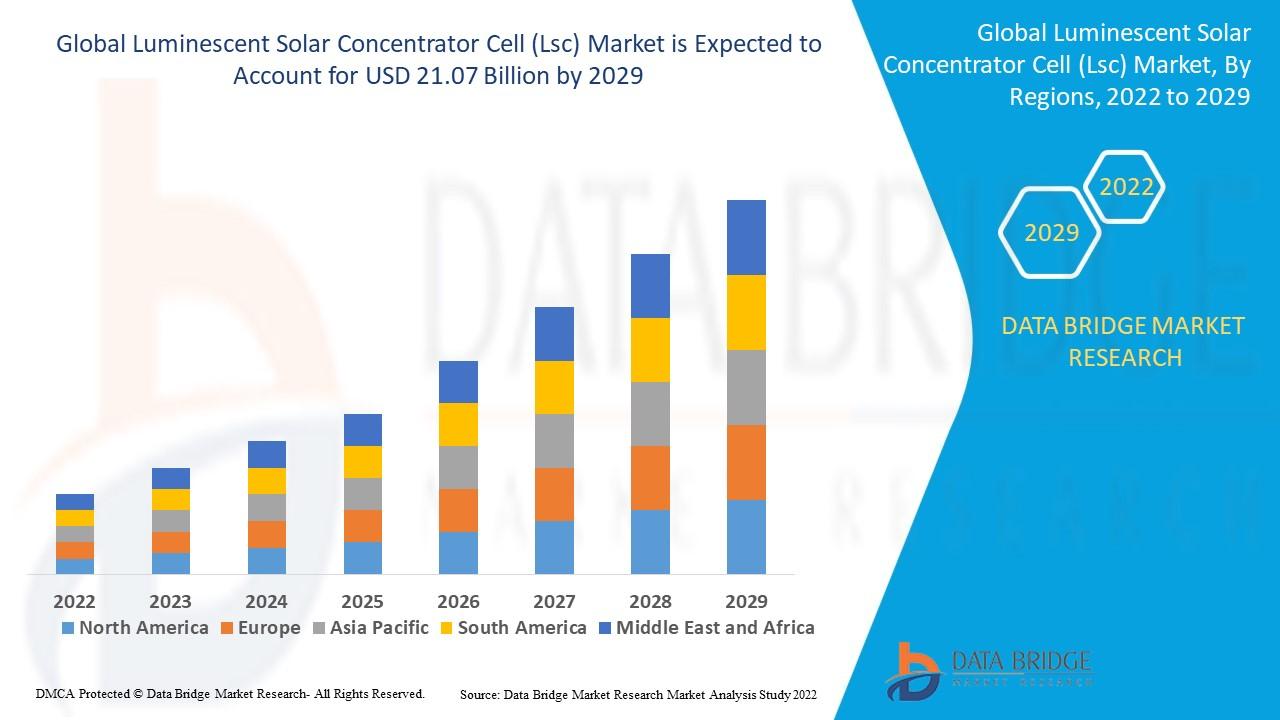
"Executive Summary Luminescent Solar Concentrator Cell (Lsc) Market Size and Share Analysis Report Global Luminescent Solar Concentrator Cell (Lsc) Market was valued at USD 2.71 billion in 2021 and is expected to reach USD 21.07 billion by 2029, registering a CAGR of 29.20% during the forecast period of 2022-2029.Luminescent Solar Concentrator Cell (Lsc) Market report objective...
Introduction to Stainless Steel Floor Drains Stainless Steel Floor Drains are a popular choice for a wide range of applications due to their durability, corrosion resistance, and aesthetic appeal. One key consideration when selecting a floor drain is its suitability for high-humidity environments such as bathrooms, basements, or industrial settings. A Stainless Steel Floor Drain Factory...

According to the latest report published by Data Bridge Market Research, the Aerospace and Life Sciences TIC Market The global aerospace and life sciences TIC market size was valued at USD 39.73 billion in 2025 and is expected to reach USD 51.92 billion by 2033, at a CAGR of 3.40% during the forecast period The large scale Aerospace and Life Sciences TIC...