


GLM 5.2: Architecture, Benchmark Performance, and What It Takes to Deploy at Scale

Open-weight large language models continue to evolve rapidly, but GLM 5.2 has emerged as one of the most notable releases in this category. Developed as the successor to GLM 5.1, the model combines frontier-level performance with a permissive MIT license and an exceptionally large 1 million token context window. These capabilities make GLM 5.2 attractive for teams exploring advanced AI deployment without being locked into proprietary ecosystems.
This article explores the architecture behind GLM 5.2, its benchmark performance, deployment requirements, and how organizations can operationalize models of this scale efficiently.
Understanding GLM 5.2
GLM 5.2 is an open-weight large language model designed to support demanding reasoning, coding, and long-context workloads. Unlike conventional dense models, GLM 5.2 uses a Mixture of Experts (MoE) architecture.
This distinction is important because MoE models activate only a portion of their total parameters for each token during inference. As a result, they can achieve strong capability while maintaining more efficient compute utilization than activating the entire parameter set continuously.
Some of the reported specifications of GLM 5.2 include:
- Approximately 753 billion total parameters
- Around 40 billion active parameters per token through MoE routing
- Native context window of 1 million tokens
- Maximum output length of up to 131,072 tokens
- Training dataset containing approximately 28.5 trillion tokens
- MIT licensing with permissive usage terms
These characteristics position GLM 5.2 as a model built not only for experimentation but also for large-scale enterprise use cases.
Architectural Improvements in GLM 5.2
Beyond scale, GLM 5.2 introduces architectural enhancements intended to improve long-context efficiency and real-world inference performance.
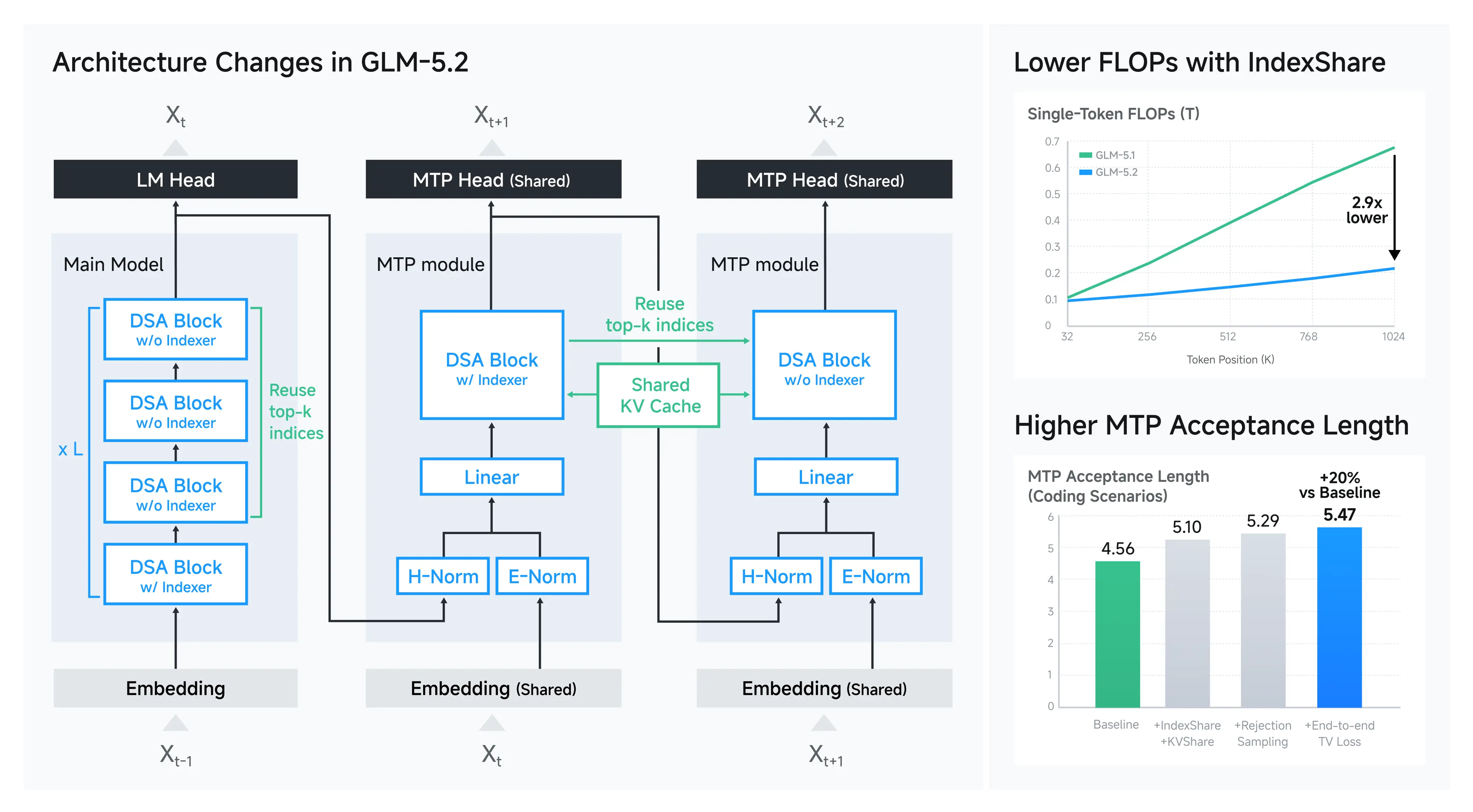
IndexShare for Efficient Sparse Attention
One of the major innovations highlighted in the release is IndexShare.
IndexShare reuses the same indexer across every four sparse attention layers. This design reduces the computational overhead associated with long-context processing.
According to reported figures, this approach can reduce per-token floating point operations significantly and delivers approximately 2.9× savings at the 1 million token context level.
For organizations running large inference workloads, this optimization directly affects cost efficiency and latency.
Improved MTP Layer for Faster Generation
GLM 5.2 also introduces enhancements to the MTP layer for speculative decoding.
The updated implementation reportedly increases acceptance length by approximately 20 percent.
In practical terms, speculative decoding improvements can accelerate generation speeds depending on the serving infrastructure and inference stack being used.
Adjustable Thinking Effort for Coding Workloads
Another practical capability is support for multiple thinking effort levels.
This enables teams to balance speed and quality depending on the application scenario.
Examples include:
- Interactive development environments where lower latency is preferred
- Large-scale batch code transformation where deeper reasoning may be prioritized
This flexibility gives teams greater control over inference economics.
Benchmark Performance of GLM 5.2
Benchmark results are one of the reasons GLM 5.2 has gained attention.
While benchmark interpretation always requires caution because output length and evaluation methodology can influence outcomes, third-party analysis suggests strong performance relative to competing open-weight systems.
One important observation from independent evaluation is that GLM 5.2 generates relatively large output volumes during tasks.
Artificial Analysis reported approximately 43,000 output tokens per task on average.
This extended reasoning behavior may improve performance on complex evaluations but also increases inference costs.
Intelligence Index Performance
GLM 5.2 reportedly reached the top position among open-weight models on the Artificial Analysis Intelligence Index.
Reported scores include:
- GLM 5.2: 51
- MiniMax M3: 44
- DeepSeek V4 Pro Max: 44
- Kimi K2.6: 43
This places GLM 5.2 ahead of several competing open-weight alternatives.
Competitive Reasoning Results
Additional evaluation results referenced in the document include:
- GDPval-AA v2 score of 1524
- Competitive positioning relative to proprietary benchmark references
The release also showed measurable improvements over GLM 5.1 across multiple evaluation categories.
Examples include:
- SWE-bench Pro
- Humanity’s Last Exam
- TerminalBench v2.1
- NL2Repo
- DeepSWE
- MCP-Atlas
- Tool-Decathlon
Collectively, these benchmarks suggest meaningful gains across software engineering, reasoning, and tool-use scenarios.
What Does It Take to Deploy GLM 5.2?
Strong benchmark performance does not automatically translate into practical deployment.
Serving GLM 5.2 introduces substantial infrastructure requirements.
Although only about 40 billion parameters are active per token, total model size still creates considerable memory pressure.
Weight Storage Requirements
The model distribution reportedly spans 282 safetensor files totaling approximately 1.51 TB.
Estimated memory requirements include:
- BF16 precision: approximately 1,506 GB
- FP8 quantization: approximately 753 GB
Quantization becomes an important lever for reducing operational cost.
KV Cache Growth at Long Context
The 1 million token context window creates an additional memory challenge through KV cache expansion.
Estimated additional memory requirements include:
- BF16 KV cache: approximately 160 GB
- FP8 KV cache: approximately 80 GB
- Runtime and activation overhead: approximately 30–60 GB
Combined serving requirements can push total deployment footprints into the 830–950 GB range.
That level of infrastructure often translates into:
- Minimum 12× H100 GPUs (80 GB)
- Or approximately 8× H200 GPUs (141 GB)
Operational Challenges
Beyond hardware capacity, production deployment introduces several system-level concerns:
- Multi-node orchestration
- Tensor and pipeline parallelism
- Quantization strategy optimization
- Attention kernel performance
- Scheduler configuration
- Speculative decoding support
- Throughput and latency balancing
Benchmark wins alone are not enough if serving economics become impractical.
Simplismart and Production Deployment
Deploying frontier-scale open-weight models requires more than simply provisioning GPUs.
Organizations must manage orchestration, infrastructure tuning, KV cache behavior, and production reliability.
Simplismart positions itself as an MLOps platform designed to reduce this operational complexity.
The platform focuses on helping teams deploy and manage GenAI workloads without building and maintaining the entire inference stack internally.
For teams evaluating GLM-family models or planning production-grade open-weight deployments, managed infrastructure approaches may reduce time to deployment while simplifying long-term operations.
Conclusion
GLM 5.2 represents a significant advancement in the open-weight AI ecosystem. With MIT licensing, a native 1 million token context window, and benchmark performance that competes with frontier systems, it demonstrates how open models continue to close the capability gap.
At the same time, deploying a model of this scale requires substantial infrastructure planning. Memory footprint, KV cache growth, multi-node coordination, and inference optimization all become critical considerations.
For organizations aiming to operationalize models at this level, combining strong model capabilities with managed deployment infrastructure can provide a more practical path to production.
Categorías
Read More
For anyone planning to work or relocate to Gulf countries, gcc medical registration is one of the most important steps before visa approval. Whether you are applying for a work visa, residence visa, or family visa for Saudi Arabia, UAE, Qatar, Kuwait, Bahrain, or Oman, the medical fitness test approved under GAMCA/Wafid is mandatory. In India, applicants regularly search for help with a gamca...

Finding the right chiropractic care can make a significant difference in your overall health and well-being. If you’re searching for a Chiropractor Fenton MI, look no further than Painless Chiropractic—a trusted name for effective, gentle, and patient-focused care. Whether you’re dealing with chronic pain, recovering from an injury, or simply looking to improve mobility,...
As per MRFR analysis, the Exhaust Sensors for Automotive Market Forecast shows significant promise over the next decade. Automotive exhaust sensors, critical for monitoring emissions and optimizing engine performance, are gaining importance as global emissions standards tighten and automakers seek improved fuel efficiency. With vehicles becoming smarter and more connected, exhaust...

Hotel guestroom furniture plays a central role in shaping the guest experience. When travelers enter a hotel room, the first impression often comes from the furniture: the bed, the desk, the seating, and the storage solutions. These elements are not merely functional; they embody the hotel’s brand identity, comfort standards, and attention to detail. In today’s competitive...
When selecting a Hair Remover Roller, understanding what fits best for your home is essential. Hair remover rollers are practical tools designed to easily pick up hair, lint, and debris from various surfaces such as furniture, carpets, and clothing. Choosing the right hair remover roller ensures a cleaner and more comfortable living environment. Opey provides a selection of hair remover rollers...
