


The Role of Image Annotation in Building Production-Grade Computer Vision Systems

Computer vision is at the core of some of the most transformative technologies of our time from self-driving vehicles to medical imaging diagnostics to retail shelf intelligence. But behind every accurate, reliable computer vision model is a foundation of precisely annotated image data. Without high-quality labels, even the most sophisticated model architecture will underperform.
Image annotation is not a commodity process. It requires domain expertise, rigorous quality assurance, and an understanding of how labeled data translates into model behavior. Digital Divide Data (DDD) has built its image annotation services around exactly these principles.
What Image Annotation Actually Involves
At its most basic, image annotation means labeling digital images with structured metadata so that machine learning models can learn from them. But in practice, the work is far more nuanced. Different tasks require different annotation techniques, each suited to a specific type of object, environment, or model objective.
DDD provides a full suite of annotation techniques, including:
• 2D bounding boxes rectangular labels around objects for detection and classification tasks
• Polygon annotation precise boundary tracing for irregularly shaped objects requiring accurate segmentation
• Semantic segmentation — pixel-level classification for scene understanding and dense prediction models
• Keypoint annotation marking joints, landmarks, and critical points for pose estimation and gesture recognition
• 3D cuboid annotation adding depth and spatial context for autonomous driving and robotic perception
• Skeletal annotation mapping body structure for biomechanical analysis and motion understanding
• Image classification assigning category labels across large datasets using custom taxonomies
Why Annotation Quality Is a Model Performance Issue
There is a direct line between annotation quality and model accuracy. Inconsistent bounding boxes, mislabeled classes, or poorly drawn polygon boundaries introduce noise into training data that compounds at scale. When a model is trained on millions of images, even a small rate of annotation error can meaningfully degrade downstream performance.
DDD addresses this through a multi-layer quality assurance framework that includes automated checks, inter-annotator review, and expert validation. The result is annotation accuracy that clients can rely on for production-grade model training.
Annotation at Scale: From Pilots to Enterprise
Many annotation providers can handle small datasets. Far fewer can maintain accuracy and consistency when projects scale to millions or hundreds of millions of images which is often the requirement for teams building enterprise-grade computer vision systems.
DDD is designed for scale. Its global delivery infrastructure, trained annotation workforce, and structured QA pipelines enable high-volume projects to run at the throughput that enterprise AI teams demand, without sacrificing quality.
Industry Applications
DDD's image annotation services support computer vision development across a wide range of industries:
• Autonomous driving and ADAS annotating vehicles, pedestrians, lanes, and obstacles for real-time perception models
• Robotics labeling objects, surfaces, and interaction points to enable robots to navigate and manipulate their environments
• Healthcare AI providing pixel-level annotation of medical images to support diagnostic models for radiology, pathology, and surgical guidance
• Retail and e-commerce enabling product recognition, planogram compliance checking, and inventory automation
• Agriculture technology annotating crop imagery, terrain data, and vegetation features for precision farming models
• Sports analytics marking athlete body positions and movements to enable performance analysis and coaching insights
• Geospatial intelligence labeling satellite and aerial imagery for mapping, land-use analysis, and defense applications
Human-in-the-Loop: The Accuracy Multiplier
DDD's annotation approach is built on the principle that human judgment is irreplaceable particularly for complex, ambiguous, and safety-critical annotations. DDD's human-in-the-loop (HITL) model combines skilled annotators with AI-assisted tools, using human expertise to handle the edge cases and contextual nuances that automated systems cannot reliably resolve.
This approach is especially important for rare scenarios the unusual, low-frequency events that have an outsized impact on model safety and robustness but are underrepresented in standard datasets.
Security and Compliance Built In
Image datasets often contain sensitive content medical scans, proprietary product imagery, private vehicle data. DDD's annotation infrastructure is designed with enterprise-grade security and compliance in mind, including SOC 2 Type 2 and ISO 27001 certifications, GDPR and HIPAA compliance, and TISAX-aligned practices for automotive and mobility clients.
Conclusion
High-quality image annotation is the foundation on which accurate computer vision models are built. DDD's combination of annotation expertise, rigorous QA, scalable infrastructure, and domain-specific knowledge makes it a trusted partner for organizations developing production-grade AI systems.
To learn more about DDD's image annotation services and how they can support your computer vision program, speak with an expert today.
Categorie
Leggi tutto
Introduction About Federico Valverde Federico Santiago Valverde Dipetta, born on July 22, 1998, in Montevideo, Uruguay, is a professional footballer who has established himself as a skilled center midfielder. Holding dual citizenship of Uruguay and Spain, Valverde’s early football development began at Peñarol, one of Uruguay’s most prominent clubs. His talent and dedication...
The Plasma Processing in Mining Market is emerging as an advanced and innovative approach to mineral extraction, material processing, and waste treatment. Plasma-based technologies utilize extremely high temperatures and reactive plasma states to enable efficient separation, smelting, and treatment of ores and mining residues. As the mining industry faces increasing pressure to improve...

Triple Green Farms CBD is a hemp-derived supplement designed to support overall wellness through the natural properties of cannabidiol (CBD). CBD is a non-psychoactive compound found in the cannabis plant, meaning it does not produce the “high” typically associated with marijuana. Instead, it works with the body’s endocannabinoid system, which helps regulate functions such as...

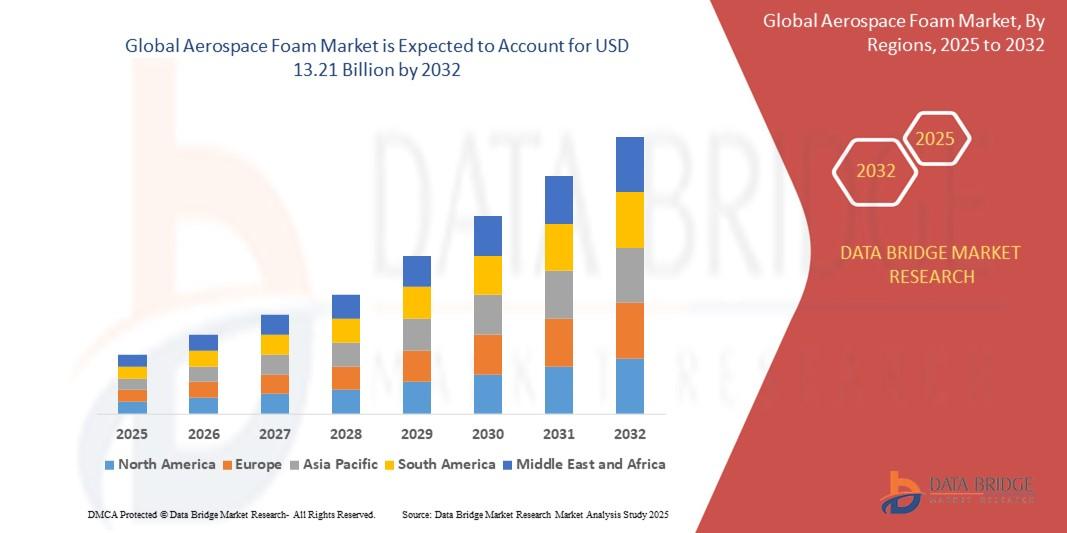
"Future of Executive Summary Aerospace Foam Market: Size and Share Dynamics CAGR Value The global aerospace foam market size was valued at USD 8.17 billion in 2024 and is expected to reach USD 13.21 billion by 2032, at a CAGR of 6.20% during the forecast period The Aerospace Foam Market report offers an analytical assessment of the prime challenges faced by...
PTW Shift Handover: The Silent Link That Keeps Industrial Safety Intact...