Analyzing the Architectural Foundations of the Modern Cluster Computing Market Platform

At its most fundamental level, the architecture of a modern Cluster Computing Market Platform is composed of three core physical components: a collection of compute nodes, a high-speed network interconnect, and a shared storage system. The compute nodes are the workhorses of the cluster, each being an independent computer typically containing one or more CPUs, memory (RAM), local storage, and a network interface. These are often referred to as "worker nodes." In addition to the workers, a cluster almost always has one or more "master nodes" (or management nodes). These specialized nodes run the software responsible for managing the entire cluster, including scheduling jobs, allocating resources to different tasks, monitoring the health and status of the worker nodes, and providing a central point of administration. The high-speed network interconnect is the nervous system of the cluster, linking all the nodes together and enabling them to communicate and exchange data. The performance of this network is critical, especially for applications where the nodes must work in close coordination. Finally, a shared storage system ensures that all nodes have access to the same data and application files, which is essential for most parallel computing tasks. The specific choice and configuration of these components are tailored to the cluster's intended purpose, such as High-Availability (HA) clusters designed for maximum uptime or Load-Balancing clusters designed to distribute web traffic.
For the purpose of Big Data processing, a set of highly influential software platforms has been built on top of this basic hardware architecture. The foundational platform that ignited the Big Data revolution was the Apache Hadoop ecosystem. Hadoop introduced a new paradigm for distributed computing, centered on two key components: the Hadoop Distributed File System (HDFS) and MapReduce. HDFS solved the problem of storing massive datasets by breaking files into large blocks and distributing them across the local drives of the cluster's nodes, providing both scalability and fault tolerance through data replication. MapReduce provided the programming model for processing this distributed data, splitting a large task into smaller "map" and "reduce" phases that could be executed in parallel across the cluster. Over time, the Hadoop ecosystem grew to include many other projects, with Apache YARN (Yet Another Resource Negotiator) becoming a crucial component for managing cluster resources and allowing multiple different processing engines to run on the same cluster. While MapReduce has largely been superseded, the principles of distributed storage and resource management pioneered by the Hadoop platform remain highly influential.
The evolution of Big Data platforms led to the rise of Apache Spark, which addressed many of the performance limitations of the original Hadoop MapReduce model. Spark's primary innovation was its ability to perform computations in-memory rather than writing intermediate results to disk, which resulted in performance improvements of up to 100 times for certain applications, particularly iterative algorithms common in machine learning. Spark introduced a more powerful and flexible programming abstraction called the Resilient Distributed Dataset (RDD), and later, the even more user-friendly DataFrame and Dataset APIs. A key reason for Spark's dominance is its unified engine, which provides a single platform for a wide range of data processing tasks. Developers can use Spark to perform large-scale batch processing, real-time stream processing (with Spark Streaming), interactive SQL queries (with Spark SQL), graph processing (with GraphX), and machine learning (with MLlib), all within a single, cohesive framework. This versatility has made Spark the de facto standard platform for large-scale data engineering and data science, running on top of resource managers like YARN or, increasingly, on Kubernetes.
The most significant recent development in cluster computing platforms has been the universal adoption of Kubernetes as the standard for container orchestration. Originally developed by Google, Kubernetes provides a powerful, open-source platform for automating the deployment, scaling, and management of applications packaged in lightweight, portable containers (like Docker). This has revolutionized how modern applications, particularly those based on a microservices architecture, are run on clusters. Kubernetes abstracts the underlying cluster hardware, presenting developers with a unified API to deploy their applications. It handles critical tasks such as scheduling containers onto available nodes, managing network connectivity between containers, providing service discovery and load balancing, and automatically restarting failed containers to ensure application resilience (self-healing). This portability and robust automation mean that an application developed to run on a Kubernetes cluster in a private data center can be moved to a Kubernetes cluster on any major cloud provider with minimal changes. This has made Kubernetes the foundational platform for modern, cloud-native computing, bridging the worlds of Big Data, AI, and general-purpose application hosting on a single, unified cluster management system.
Explore More Like This in Our Regional Reports:
Categorias
Leia mais
In today’s fast-paced digital world, businesses are under constant pressure to process data faster, respond in real time, and reduce dependency on centralized cloud systems. This demand has led to the rise of edge ai solutions, a powerful approach that brings artificial intelligence directly to the source of data generation. Instead of sending massive volumes of data to distant cloud...

Introduction IV Drip at Home in Dubai is an effective way to enhance immunity and support recovery. With a professional doctor at home, you can receive personalized IV therapy that replenishes fluids, delivers essential vitamins, and promotes overall wellness without visiting a clinic. How IV Therapy Supports Immunity and Recovery IV drips deliver nutrients and fluids directly into the...
The Streetwear Brand Blending Music, Luxury, and Urban Fashion: Few fashion labels have shaped modern streetwear culture the way OVO has. Known for its clean aesthetics, luxury appeal, and strong connection to music culture, OVO has become one of the most influential names in contemporary fashion. The brand stands for “October’s Very Own,” a name closely linked to...

In today’s fast-moving digital world, impatience has become normal. People expect instant responses, quick results, and constant stimulation. Gaming has not been immune to this trend. However, as platforms evolve and players mature, a clear shift is taking place. Discipline and patience are emerging as the most valuable skills for long-term success. Mahadev Book reflects this change...

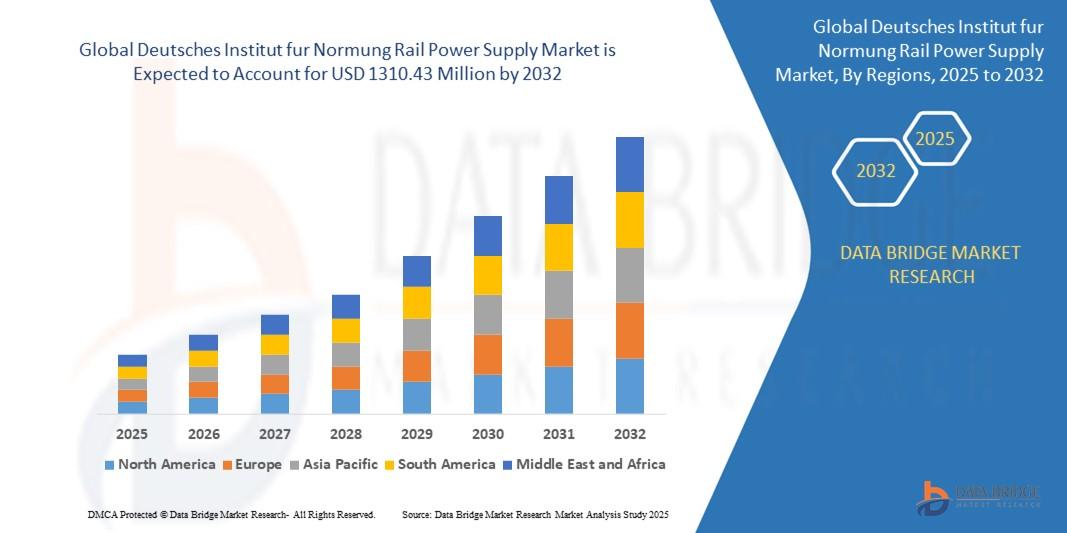
Global Demand Outlook for Executive Summary DIN Rail Power Supply Market Size and Share CAGR Value The global deutsches institut fur normung rail power supply market size was valued at USD 987.49 million in 2024 and is expected to reach USD 1310.43 million by 2032, at a CAGR of 3.60% during the forecast period The wide-ranging report deals with the new...