


Evaluating Modern Temporal Storage Architectures
In the rapidly evolving landscape of big data, selecting the right storage engine is critical for maintaining high operational performance. Many organizations begin their journey by attempting to utilize tsdb elasticsearch configurations for time-stamped telemetry, seeking to leverage existing search infrastructure for analytical workloads. While general-purpose search engines provide excellent full-text capabilities, specialized time-series databases are designed with unique internal optimizations—such as columnar storage and time-partitioning—that significantly enhance the efficiency of chronological data ingestion and retrieval. Understanding these architectural differences allows engineering teams to build more resilient data pipelines that can handle the high-velocity streams characteristic of modern industrial and IIoT applications.
The Significance of Purpose-Built Data Engines
When architecting a system for time-indexed data, the primary objective is to maximize ingestion throughput while minimizing query latency over historical intervals. Purpose-built time-series databases are engineered to treat time as a first-class citizen, meaning they handle temporal data natively rather than relying on external indexing structures that may consume excessive resources. By aligning the storage layout with the way data is accessed—typically in time-sequential order—these databases reduce the amount of physical disk I/O required to satisfy complex analytical queries.
This native handling of time facilitates advanced features like automated downsampling, which aggregates high-resolution data into summarized buckets as it ages. Such functionality is vital for maintaining long-term visibility without incurring the massive storage costs associated with keeping every raw data point indefinitely. Consequently, platforms that prioritize these temporal optimizations offer a more sustainable path for enterprises dealing with exponential data growth.
Exploring the Landscape of Temporal Storage
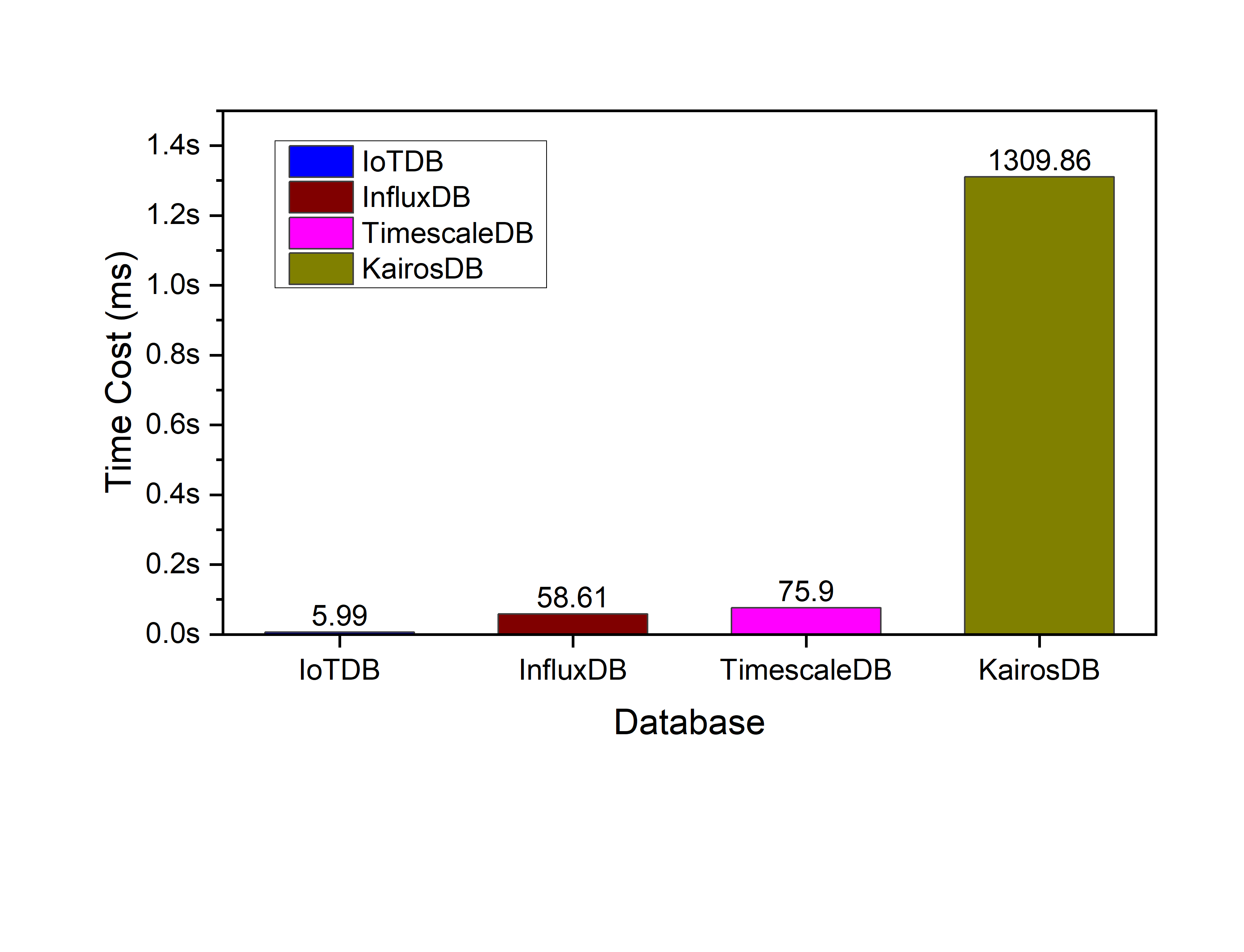
For many architects, the decision-making process involves a comprehensive open source time series database comparison to determine which solution best fits their unique operational requirements. This evaluation typically covers key performance indicators such as write-heavy throughput, storage compression ratios, and the availability of sophisticated query languages designed for trend analysis. By assessing these metrics, organizations can ensure that their chosen platform provides the necessary tools for real-time monitoring and advanced predictive maintenance.
The shift toward specialized databases is driven by the need for consistency and predictability in analytical workloads. When a system is specifically optimized for time-series data, it offers predictable performance levels even as the dataset grows into the multi-terabyte range. This stability is essential for applications where system uptime and immediate data availability are non-negotiable, providing a reliable foundation for both operational dashboards and automated machine learning pipelines.
Administrative Features and Reliability
Maintaining a robust temporal data ecosystem requires sophisticated tools for data protection and recovery. When implementing timescaldb tsdb snapshot procedures, administrators ensure that they have a reliable mechanism for creating point-in-time backups that can be used to restore the system in the event of hardware failure or accidental data loss. These snapshot capabilities are central to maintaining the integrity of industrial telemetry, allowing teams to preserve the state of their database without interrupting the continuous flow of incoming sensor data.
Effective snapshot management is a hallmark of a mature data infrastructure. By automating these processes, engineering teams can guarantee that historical records are safe and accessible for audit purposes or long-term trend analysis. This reliability enables organizations to focus on extracting insights from their data rather than worrying about the underlying maintenance of their storage systems, ultimately driving higher productivity across technical teams.
Optimizing Query Performance and Indexing
To achieve the best possible performance, it is vital to understand how indexing works within a temporal database. By employing tag-based indexing, databases can isolate specific metrics associated with individual assets, process lines, or geographic regions. This indexing strategy allows the query engine to prune the search space before executing a scan, which dramatically reduces the amount of data processed during each request.
When combined with time-based partitioning, this approach ensures that queries targeting a specific timeframe—such as the last 24 hours—are processed with near-instant speed. By focusing compute resources only on the relevant partitions, the database remains highly responsive regardless of how much historical data has been accumulated in the archival layers. This efficiency is the cornerstone of a performant monitoring environment.
The Role of Tiered Storage in Cost Efficiency
As datasets expand, managing the balance between performance and cost becomes increasingly important. Implementing a tiered storage strategy allows organizations to move aged data from high-performance memory or SSD storage to more economical high-density disk storage. This transition is usually automated, ensuring that "hot" data remains instantly accessible while "cold" data is kept in an optimized format for later retrieval.
This approach provides a significant competitive advantage by allowing companies to store years of historical data without inflating their operational budget. By intelligently managing data placement, organizations can maintain a lean and fast "hot" layer that supports real-time anomaly detection, while simultaneously fulfilling all long-term regulatory or analytical retention requirements within their archival storage tiers.
Securing the Temporal Data Pipeline
Security is a foundational element in modern industrial data management. Protecting the data pipeline means securing every stage, from the edge device sending telemetry to the storage backend where it resides. Implementing role-based access control (RBAC) allows administrators to define precisely which users can view, modify, or query specific metrics.
Furthermore, ensuring that data is encrypted both at rest and in transit provides an additional layer of protection against unauthorized access. By adopting hardened security protocols, organizations can shield their proprietary operational insights, maintaining compliance with global industry standards and protecting the fundamental data that drives their business operations. A comprehensive security posture is essential for any long-term industrial intelligence strategy.
Future-Proofing with Predictive Analytics
The culmination of a well-architected data strategy is the ability to leverage historical patterns for predictive forecasting. When a temporal database is efficiently tuned, it acts as a reliable source of truth for machine learning models that detect early warning signs of equipment degradation. This transition from reactive troubleshooting to proactive maintenance is a primary driver of operational ROI in the industrial sector.
By feeding high-quality, structured data into these models, organizations can effectively anticipate maintenance needs and optimize their resource scheduling. This shift not only prevents unplanned downtime but also extends the operational life of critical assets. As companies continue to invest in smarter infrastructure, the ability to turn chronological data into actionable foresight will become the definitive marker of industrial leadership.
Conclusion
Navigating the complexities of tsdb elasticsearch integration, performing a thorough open source time series database comparison, and mastering the timescaldb tsdb snapshot processes are all fundamental to building a high-performance industrial intelligence environment. By focusing on specialized storage architectures, efficient indexing, and tiered lifecycle management, organizations can ensure that their data infrastructure supports their long-term operational goals. As industrial ecosystems continue to expand, the ability to store and analyze chronological information with speed and precision will remain a cornerstone of competitive advantage. Through careful planning and the adoption of purpose-built temporal storage technologies, enterprises can secure their path to operational excellence in an increasingly data-driven world.
Categorias
Leia mais
In an increasingly hygiene-focused world, where surface contamination poses persistent risks to health, food safety, and infrastructure, antimicrobial nanocoatings are revolutionizing surface protection with intelligent, long-lasting defenses at the nanoscale. The global antimicrobial nanocoatings market size was valued at USD 290.22 million in 2024 and is expected to...

Online auctions have transformed the way buyers and sellers interact, making the bidding process faster and more convenient than ever before. One important feature that helps streamline this process is proxy bidding. Yet many users still ask, what is a proxy bid, and misunderstand how it works. Some believe it gives unfair advantages, while others assume it is too complicated to use. In...

In a city celebrated for its cultural diversity and global outlook, early education plays a vital role in shaping the next generation of open-minded and responsible citizens. A nursery Dubai Marina stands as more than just a place for early childhood learning—it serves as a gateway to global awareness, empathy, and cross-cultural understanding. Situated in one of Dubai’s most...

A PR agency UAE helps businesses build brand awareness, manage public relations, and enhance reputation through strategic communication, media coverage, and digital PR. A professional UAE PR agency creates customized campaigns, connects brands with media platforms, and ensures a strong public image to support long-term business growth. Introduction The United Arab Emirates is one of the...

Easy and Trusted Palo Alto Networks Cybersecurity-Practitioner Exam Prep for Fast Results Many students feel confused before Palo Alto Networks Cybersecurity-Practitioner exams. They study many books but still feel unsure. This wastes time and energy. Good Palo Alto Networks Cybersecurity Practitioner certification exam preparation material helps fix this problem in a...
