


Understanding Data Pipelines at a High Level
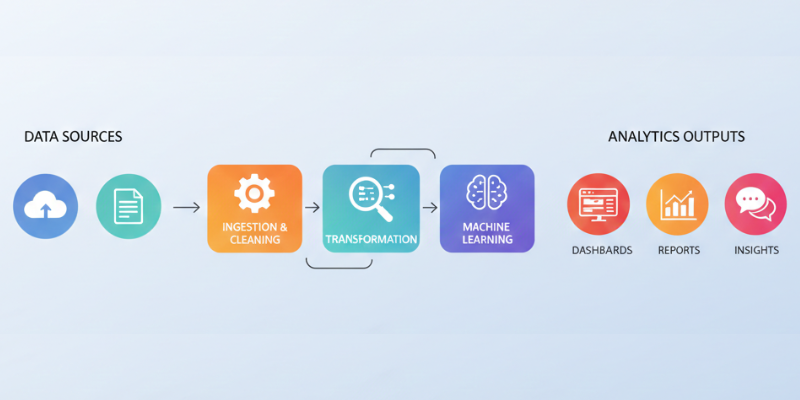
Organizations rely on smooth data movement to make informed decisions. This is where data pipelines play a critical role by enabling data to flow from multiple sources to usable destinations. At a high level, a data pipeline is a structured process that collects, processes, and delivers data so it can be analyzed effectively.
For those looking to establish a solid base in analytics, understanding this concept is essential, and if you are looking to strengthen these fundamentals, you may consider enrolling in Data Analytics Courses in Bangalore at FITA Academy to gain practical exposure and industry-oriented knowledge that supports real learning outcomes.
What a Data Pipeline Actually Does
A data pipeline ensures that raw data does not stay scattered or unused. It gathers data from different sources, such as applications, databases, or external systems, and moves it through a defined process. During this movement, data may be cleaned, organized, or structured to make it suitable for analysis. The goal is to deliver reliable and timely data to analysts, dashboards, or reporting tools without manual effort.
Core Components of a Data Pipeline
Every data pipeline is built using a few essential components that work together. The first component is the data source, where information originates. The second is data processing, where transformations such as filtering or formatting occur. The final component is the destination, which could be a data warehouse, analytics tool, or visualization platform. These components operate in sequence to maintain data consistency and accuracy throughout the pipeline.
Types of Data Pipelines
Data pipelines generally fall into two main types based on how data is processed. Batch pipelines move data in groups at scheduled intervals, which works well for historical reporting. Real-time pipelines process data continuously as it is generated, which is useful for monitoring and immediate insights.
Understanding these types helps analysts choose the right approach based on business needs, and learners exploring structured analytics training, such as a Data Analytics Course in Hyderabad often gain clarity on how and when each pipeline type is applied in real scenarios.
Why Data Pipelines Matter in Analytics
Without data pipelines, analytics becomes slow, error prone, and heavily dependent on manual work. Pipelines automate repetitive tasks and ensure that data arrives in a ready-to-use format. This allows analysts to focus more on discovering insights rather than preparing data. Consistent pipelines also improve data quality, which directly impacts the accuracy of reports and decisions made from them.
Common Challenges in Data Pipelines
Despite their benefits, data pipelines come with challenges that need careful handling. Data quality issues, system failures, and scaling problems can affect pipeline performance. Poorly designed pipelines may also introduce delays or inconsistencies. Addressing these challenges requires clear design, monitoring, and an understanding of how data behaves as it moves through different systems.
How Data Pipelines Support Business Growth
Reliable data pipelines help organizations respond faster to changes and opportunities. They provide decision makers with up-to-date information, enabling better planning and performance tracking. As businesses grow, pipelines also make it easier to handle increasing data volumes without disrupting operations. This makes them a foundational element of any mature data analytics strategy.
Understanding data pipelines at a high level helps beginners connect technical processes with real business value. These pipelines act as the backbone of analytics by ensuring data flows smoothly from source to insight. For those who want to deepen their understanding and apply these concepts confidently in real projects, taking a Data Analytics Course in Ahmedabad can be a practical step toward building strong analytics skills and advancing your career with structured learning support.
Also check: The Principle of Simplicity in Data Visualization
Categories
Read More
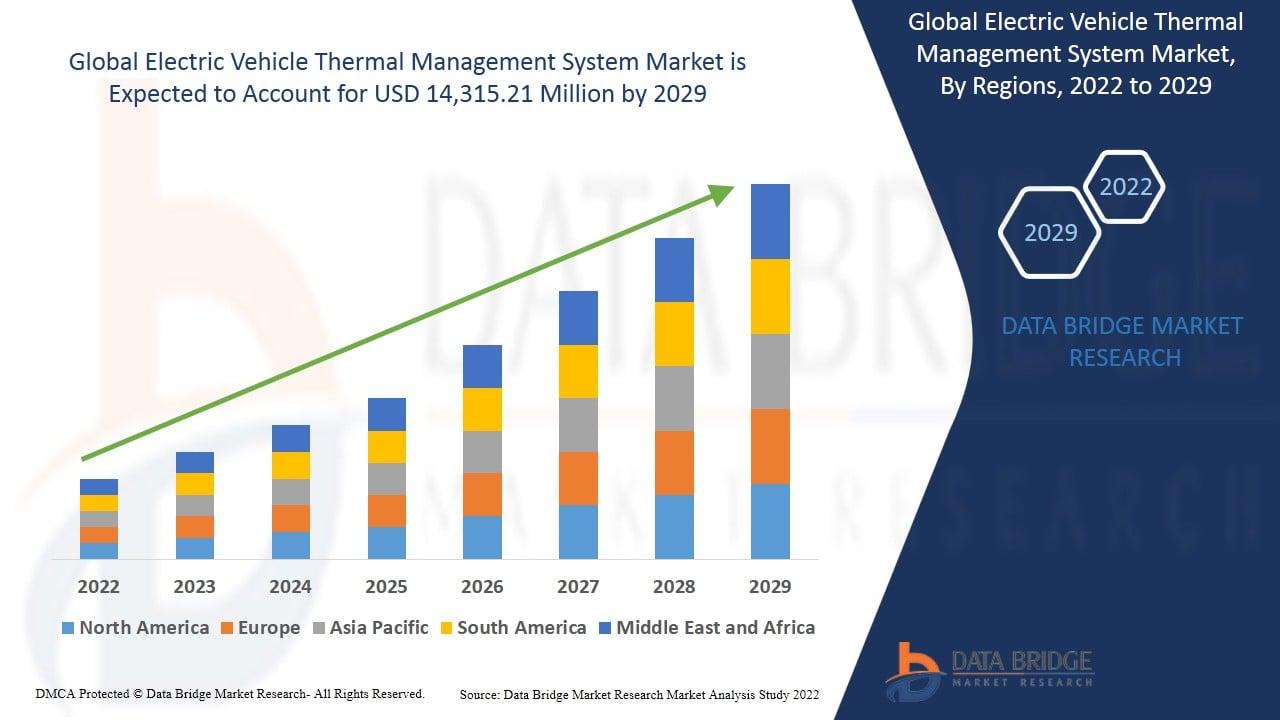
According to the latest report published by Data Bridge Market Research, the Electric Vehicle Thermal Management System Market Data Bridge Market Research analyses that the electric vehicle thermal management system market is expected to reach the value of USD 14,315.21 million by 2029, at a CAGR of 24.1% during the forecast period. This Electric Vehicle Thermal Management System...
Custom Curtain Solutions for Large Windows Getting the details right makes a big difference when it comes to large windows. Things like curtain length, width, and where they are installed often matter more than the style itself. When these elements are off, even a well-designed room can feel slightly unbalanced. Instead of focusing only on decoration, it helps to think about how...
The excitement surrounding Bigg Boss 20 is growing as fans eagerly await the return of India’s most popular reality television display. Taken together, known for its intense competition, celebrity contestants, emotional moments, and unexpected twists, Bigg Boss has become a household name over the years. With the twentieth season on the horizon, viewers are already searching for reliable...
The arts have a profound impact on the development of youth and the overall well-being of adults. When you choose to dance, you are choosing to invest in your physical health, mental sharpness, and emotional expression. This journey is best taken in a professional setting that prioritizes the growth of the individual above all else. Exploring Artistic Excellence at Campbell River Dance Studios...

When it comes to creating a warm, cohesive, and luxurious atmosphere in your home or office, few flooring options rival the elegance and comfort of a wall-to-wall carpet. In the bustling interiors of Dubai, where style meets modern living, investing in a full-room carpet can turn any space into a sanctuary of soft textures and refined design. Why Choose Wall-to-Wall Carpets? Seamless...