


Radar Annotation for Sensor Fusion: The Cross-Modal Consistency Challenge
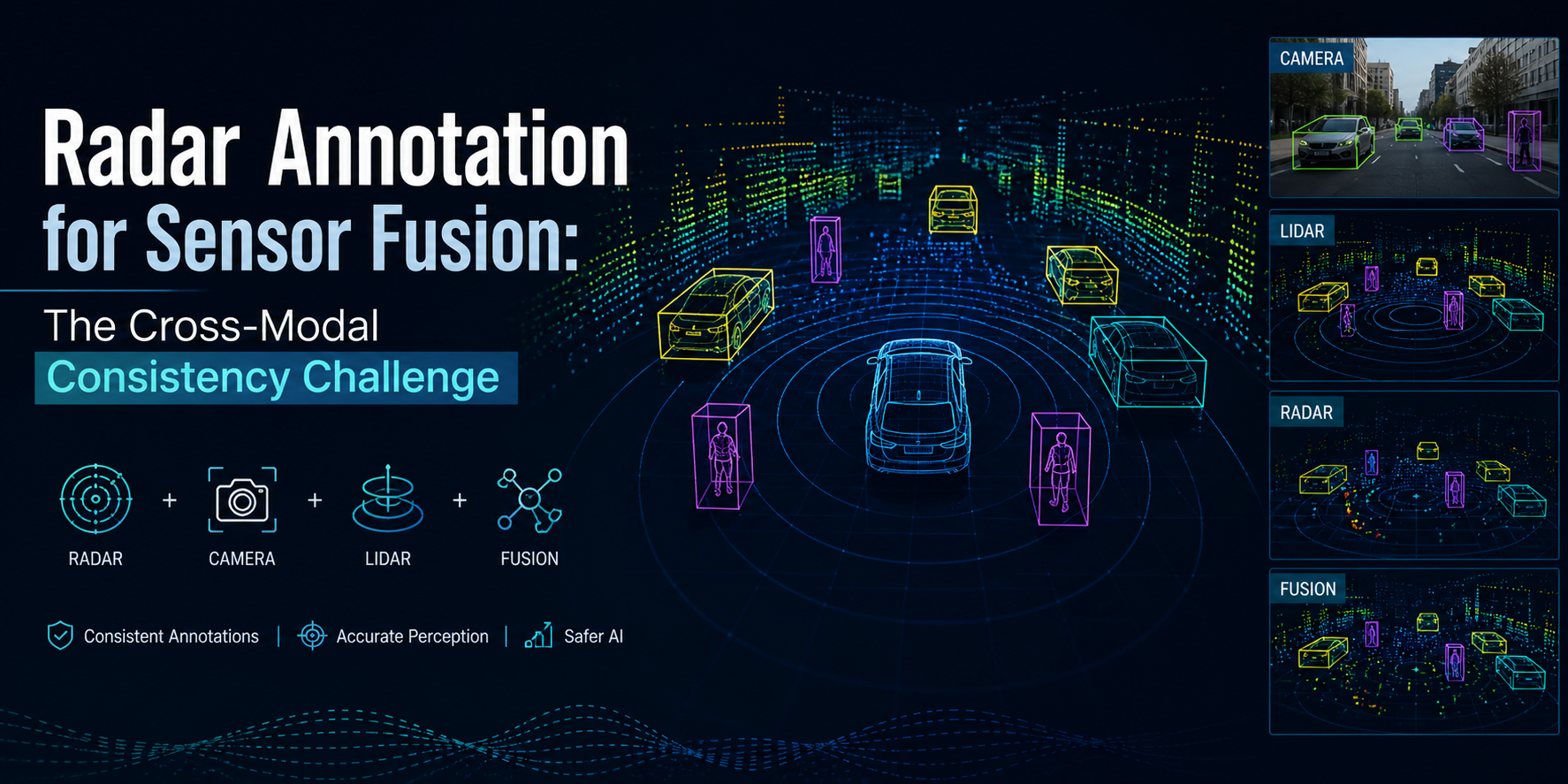
A vehicle detected at 45 meters by radar, labeled as "car" in the radar annotation, should be the same vehicle appearing in the camera frame as a bounding box labeled "car," and in the LiDAR point cloud as a 3D cuboid labeled "car" all with the same spatial position, the same track ID, and at the same timestamp.
That seems straightforward. In practice, maintaining cross-modal consistency across radar, camera, and LiDAR annotation at production scale is one of the most technically demanding annotation challenges in autonomous driving development. And it is the dimension that sensor fusion perception models most directly depend on because the fusion model's ability to correctly combine inputs from all three sensors depends on the training data teaching it consistent associations between what each sensor sees.
Why Sensor Fusion Needs Cross-Modal Annotation Consistency
Sensor fusion perception models the systems that combine camera, LiDAR, and radar inputs into a unified environmental model learn those combination rules from training data. The training data needs to show the model what camera, LiDAR, and radar returns from the same object look like simultaneously, so the model learns to associate a radar detection cluster with its camera appearance and its LiDAR spatial representation.
If the annotation is inconsistent across modalities if the radar annotator labeled a vehicle as "van" while the camera annotator labeled the same vehicle as "truck" the fusion model trains on contradictory labels for the same object. It cannot learn a reliable association between the radar, camera, and LiDAR signatures of that vehicle class because the training data presents inconsistent ground truth.
Inconsistency at the class label level is the easiest type to detect. Inconsistency at the spatial extent level where the camera bounding box and the radar detection cluster correspond to slightly different object footprints due to sensor-specific coverage characteristics is harder to detect and harder to correct. Inconsistency at the temporal alignment level where annotations in different sensor streams are assigned to slightly different timestamps due to sensor hardware synchronization offsets is hardest to detect and produces the subtlest but potentially most consequential fusion model errors.
The Three Layers of Cross-Modal Consistency in Radar Annotation
Layer 1: Semantic Label Consistency
The object class taxonomy needs to be defined once, shared across all sensor modalities, and applied consistently by all annotators regardless of which sensor modality they work with. A taxonomy that uses "passenger vehicle" in camera annotation and "car" in radar annotation produces inconsistencies that look like different label choices but actually represent the same annotation problem.
Semantic label consistency is enforced at the ontology definition level: a single taxonomy document that defines every object class, its visual and sensor-specific characteristics in each modality, and the decision rules for ambiguous cases (when does a vehicle become a "van" versus a "truck"). Every annotator across all modalities uses this document. Any new class added to the taxonomy gets simultaneously updated across all modality guidelines.
For radar specifically, the taxonomy needs to include characteristics that help radar annotators make consistent class decisions from sparse detection data: the typical RCS signature ranges for each class, the typical detection cluster size and pattern for each class at standard ranges, and the class ambiguity rules that govern decisions when the radar data is insufficient to clearly distinguish between classes that have similar radar signatures (pedestrians and cyclists at long range, for example).
Layer 2: Spatial Consistency Across Sensor Modalities
Each sensor perceives objects from a different physical vantage point, with different resolution characteristics, and at different effective coverage ranges. Camera bounding boxes define object extent in the image plane. LiDAR cuboids define object extent in 3D space based on point cloud coverage. Radar bounding boxes define object extent in range-azimuth space based on detection cluster footprint.
These representations are not directly equivalent, but they need to be spatially consistent — meaning that when projected into a common coordinate frame, they should cover the same object with the same orientation. Cross-modal spatial validation checks this correspondence by projecting all sensor-modality annotations into a common world coordinate frame and verifying that the annotated extents overlap correctly.
Radar-specific spatial consistency challenges include:
Specular return offset: Radar detections concentrate on the most reflective surfaces of an object, not at its geometric boundary. The front bumper and rear bumper of a vehicle may return strong radar detections, while the sides return little or nothing. The annotated radar extent may appear narrower in azimuth and shallower in range than the vehicle's actual physical footprint as represented in the camera and LiDAR annotations. Guidelines need to specify how to handle this radar-specific bias in spatial extent annotation.
Sensor coverage overlap: Radar typically has a narrower field of view than camera or LiDAR in many configurations. Objects at the edge of the camera frame may be visible in camera and LiDAR but outside radar coverage. The cross-modal annotation program needs clear rules for objects detected in some sensor modalities but not others how to handle the absence of radar annotation for objects that camera and LiDAR detect at the edge of radar's field of view.
Range resolution effects: Radar range resolution creates a minimum separation below which two objects cannot be distinguished in range. Two vehicles that are 2 meters apart in range may appear as a single merged radar detection cluster, while camera and LiDAR clearly show two separate vehicles. Guidelines need to specify how to annotate radar data for close-proximity objects that the range resolution prevents from being separated.
Layer 3: Temporal Consistency and Synchronization
Sensors operate at different sampling rates and have different hardware latency characteristics. A camera may capture frames at 30 Hz. A LiDAR may scan at 10 Hz. A radar may update at 20 Hz. The temporal misalignment between sensor frames which frames from different sensors represent the same physical moment needs to be established through hardware synchronization metadata before cross-modal annotation can be performed consistently.
When hardware synchronization data is available (GPS-referenced timestamps from sensor hardware), temporal alignment across modalities is straightforward. When it isn't when sensor timestamps use internal clocks with different epochs or drift characteristics temporal alignment requires interpolation that introduces positional uncertainty for fast-moving objects.
Radar annotation programs for sensor fusion data need explicit procedures for timestamp handling: what temporal alignment metadata is available, how to assign sensor frames to common timestamps, and how to handle the positional uncertainty that temporal interpolation introduces when synchronization is imperfect.
Quality Assurance for Cross-Modal Radar Annotation
Standard single-modality quality assurance checks accuracy within a modality: is this radar detection cluster labeled correctly, is the bounding box placed correctly relative to the detection cluster, is the velocity label physically plausible. These checks don't address cross-modal consistency.
Cross-modal quality assurance requires additional review processes specifically designed to verify consistency across sensor modalities:
Class label cross-check: For each object appearing in multiple sensor modalities, verify that the class label is identical across all modalities where the object appears. Automated cross-modal comparison tools can flag all instances where an object's class label differs across radar, camera, and LiDAR annotations.
Spatial correspondence verification: Project annotations from all modalities into a common coordinate frame and verify that the spatial extents correspond correctly, accounting for the sensor-specific coverage characteristics that create legitimate differences in annotated extent. Annotations where the spatial correspondence falls outside expected bounds for the sensor modalities involved get flagged for expert review.
Track ID consistency check: For each track ID assigned in radar annotation, verify that the same track ID is used in camera and LiDAR annotations for the same real-world object across the full temporal span where the object appears in all modalities. Track ID mismatches where the same physical object has different IDs in different sensor modalities directly corrupt the training signal for sensor fusion tracking models.
Velocity cross-validation: Compare radar-annotated velocities against the velocities implied by frame-to-frame position changes in camera and LiDAR annotations for the same object. Systematic differences between radar-annotated velocity and optically-derived velocity estimates indicate either annotation errors in the radar velocity labels or errors in the spatial annotations that produce incorrect optical velocity estimates.
The Sensor Fusion Training Data Quality Standard
Sensor fusion models trained on well-annotated cross-modal data develop a qualitatively different capability than models trained on separately annotated single-modality data stitched together without consistency validation. The fusion model trained on consistent cross-modal data learns correct associations between what each sensor sees for each object class which is what enables it to correctly handle the scenarios where one sensor's reliability advantage needs to compensate for another sensor's limitation.
A fusion model that learned from inconsistently annotated training data develops confused associations: the radar signature of one class gets partially associated with the camera signature of a different class because the training data mislabeled instances of those classes inconsistently across modalities. The model's fusion decisions in production environments reflect those confused associations producing unexpected behaviors in exactly the scenarios where the fusion model is supposed to outperform single-modality perception.
Production-grade sensor fusion annotation programs treat cross-modal consistency as a first-class quality requirement not as an optimization applied after the core annotation work is complete, but as a constraint that shapes the annotation program design from the start. Cross-modal ontology definition, synchronized annotation workflows, and explicit cross-modal QA processes are built into the program before any annotator labels any data, because retrofitting cross-modal consistency after single-modality annotation is complete costs more and produces less reliable results than building it in from the beginning.
Final Thought
Radar annotation for sensor fusion is not radar annotation plus a consistency check. It is a fundamentally different annotation program design that treats cross-modal consistency as the primary quality dimension more important than within-modality accuracy, because within-modality accuracy without cross-modal consistency produces training data that corrupts the fusion model's core capability.
The sensor fusion models that reliably outperform single-modality perception in production environments were trained on data where the associations between radar, camera, and LiDAR representations of the same objects were correctly and consistently annotated. That consistency is the product of annotation programs designed with cross-modal requirements at their center.
Categorias
Leia mais
The global Fire Protection Materials for Construction Market was valued at US$ 6.86 Billion in 2025 and is projected to reach US$ 13.08 Billion by 2034, registering a CAGR of 8.40% during the forecast period from 2026 to 2034. Rising demand for passive fire protection systems in commercial and industrial construction, combined with increasingly stringent fire safety codes worldwide, continues...

Während die Spannung auf die Ergebnisse der Team-des-Jahres-Abstimmung noch anhält, tauchen bereits erste Hinweise auf die kommenden EA Sports FC 26 TOTY-Icons auf. Bei diesem Event wird traditionell eine spezielle Auswahl an Fußballlegenden vorgestellt, die mit verbesserten Karten versehen werden und somit ihre regulären Ikonen übertreffen. Im Fokus stehen diesmal...
Motorola Solutions appoints Peter Leav to its Board of Directors, strengthening the company’s leadership with a veteran technology executive known for guiding major enterprise software organizations. The appointment reflects the company’s focus on advancing innovation in mission-critical safety and security technologies. Leav brings more than 25 years of experience leading large...

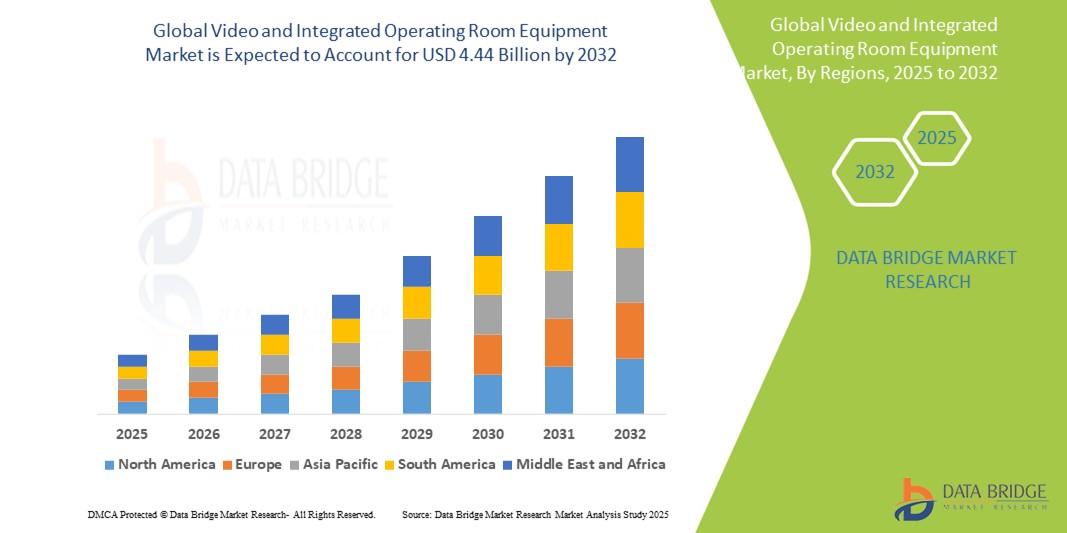
"Executive Summary Video and Integrated Operating Room Equipment Market Research: Share and Size Intelligence CAGR Value The global video and integrated operating room market was valued at USD 2.44 billion in 2024 and is expected to reach USD 4.44 billion by 2032 Market research studies stated in this Video and Integrated Operating Room Equipment Marketreport are very thoughtful for...
What Is Injection Mold Clamps? Injection Mold Clamps is a critical manufacturing process that has become indispensable across multiple industries, including automotive, medical devices, consumer electronics, and industrial applications. This technology enables the efficient production of high-precision plastic and metal components with complex geometries, excellent surface finish, and...