


GPU Infrastructure for Modern AI Training Workloads
Introduction
As artificial intelligence systems continue to scale in complexity, compute infrastructure has become one of the primary constraints on model development. Modern neural networks—especially deep learning architectures such as transformers, diffusion models, and large language models—require enormous computational throughput, memory bandwidth, and parallel processing efficiency. Traditional CPU-based systems struggle to meet these demands, which has driven widespread adoption of specialized hardware designed specifically for accelerated computation.
At the center of this shift is the gpu for ai training, which enables efficient execution of tensor-heavy workloads that dominate modern machine learning pipelines. By offloading parallelizable operations from general-purpose processors to massively parallel accelerators, GPU-based systems significantly reduce training time while improving scalability and reproducibility.
Why GPUs Are Fundamental to AI Training
In practical terms, a gpu for ai training is optimized to handle the dense linear algebra operations that underpin neural network training. Operations such as matrix multiplication, convolution, and attention mechanisms are computationally expensive but highly parallelizable—making them ideal candidates for GPU acceleration.
GPUs achieve this through thousands of lightweight cores capable of executing the same instruction across large datasets simultaneously. This architecture aligns closely with the needs of backpropagation, where gradients must be computed and applied across millions or billions of parameters. Compared to CPUs, GPUs deliver higher throughput per watt and per dollar for these workloads, especially when combined with optimized libraries such as CUDA, cuDNN, and NCCL.
Compute Architecture and Precision Considerations
A modern gpu for ai training relies heavily on specialized compute units such as Tensor Cores, which are designed to accelerate mixed-precision arithmetic. Training models using FP16, BF16, or FP8 formats reduces memory footprint and increases throughput without significantly sacrificing numerical stability when implemented correctly.
However, raw compute capability alone does not determine training performance. Kernel fusion, memory access patterns, and instruction scheduling all play a critical role. Poorly optimized kernels can underutilize GPU resources, leading to lower effective throughput despite high theoretical FLOPS. This is why software frameworks and compiler optimizations are just as important as hardware specifications.
Memory Bandwidth and Model Scaling
As model sizes grow, memory constraints become a dominant bottleneck. A gpu for ai training must support not only high compute density but also sufficient memory bandwidth to feed data into execution units without stalls. High Bandwidth Memory (HBM) plays a critical role here, enabling sustained data transfer rates that are orders of magnitude higher than traditional DRAM.
Large models also require careful memory management strategies, including gradient checkpointing, activation recomputation, and parameter sharding. These techniques trade additional computation for reduced memory usage, allowing larger models to fit within available GPU memory while maintaining acceptable training speed.
Multi-GPU and Distributed Training Topologies
Single-GPU setups are no longer sufficient for state-of-the-art models. Scaling training across multiple accelerators introduces communication overhead that can quickly negate compute gains if not handled correctly. A gpu for ai training environment must therefore support high-bandwidth, low-latency interconnects such as NVLink or high-speed Ethernet fabrics.
Distributed training strategies—data parallelism, tensor parallelism, and pipeline parallelism—each impose different demands on interconnect topology and synchronization efficiency. Selecting the right combination depends on model architecture, batch size, and available network bandwidth. Inefficient communication patterns can result in idle GPUs and reduced overall utilization.
Storage, I/O, and Data Pipelines
Compute acceleration alone does not guarantee efficient training. Data ingestion pipelines must deliver training samples to GPUs at a rate that keeps them saturated. Slow disk access, insufficient caching, or poorly sharded datasets can cause GPUs to idle while waiting for data.
An optimized gpu for ai training setup typically integrates high-performance NVMe storage and parallel data loaders to minimize I/O latency. Checkpointing large models also places significant stress on storage subsystems, making throughput and reliability critical factors in long-running training jobs.
Reliability and Long-Running Workloads
Training large models often involves continuous execution over days or weeks. Hardware instability, memory errors, or network interruptions can result in lost progress and wasted compute resources. For this reason, production-grade GPU environments emphasize monitoring, fault detection, and recovery mechanisms.
A stable gpu for ai training configuration prioritizes sustained performance and predictability over peak benchmark scores. From an engineering perspective, consistent throughput and low failure rates are often more valuable than marginal gains in raw speed.
Conclusion
Effective AI training is no longer defined solely by algorithmic innovation; it is increasingly shaped by infrastructure design choices. GPUs provide the parallelism, memory bandwidth, and scalability required to train modern models efficiently, but realizing their full potential requires careful attention to architecture, software optimization, and system integration.
As models continue to scale, the role of the gpu for ai training will only become more central. Teams that understand the interaction between compute, memory, networking, and storage are better positioned to build systems that are not only fast, but also reliable and cost-efficient over the long term.
Categorias
Leia Mais
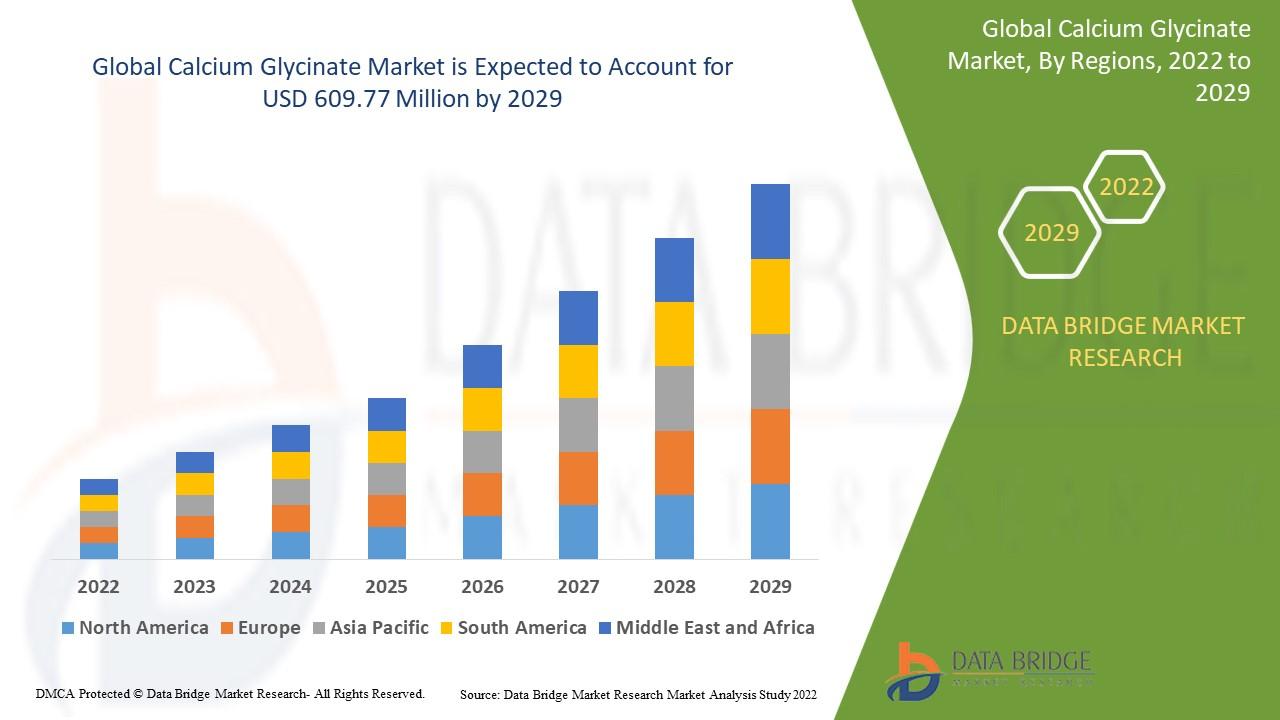
"Executive Summary Calcium Glycinate Market Size and Share Analysis Report Data Bridge Market Research analyses that the calcium glycinate was valued at 347.03 million in 2021 and is expected to reach the value of USD 609.77 million by 2029, at a CAGR of 7.30% during the forecast period.Calcium Glycinate Market report objective analysis is employed to make decisions that will not only...
The latest business intelligence report released by Polaris Market Research on Customer Data Platform Market Share, Size, Trends, Industry Analysis Report, By Vertical (BFSI, Retail & E-commerce, Media & Entertainment, Travel & Hospitality, IT & Telecom, Healthcare, Others); By Component; By Deployment Mode; By Application; By Region; Segment Forecast, 2022 - 2030. It...
As 2026 begins, recent insights from industry analysts shed light on gaming trends from the previous year. Data from 2025 highlights a persistent dominance of long-standing live-service titles across both Xbox and PlayStation platforms. Interestingly, despite the release of numerous high-profile titles from both AAA and indie developers, veteran games continue to capture the majority of player...
Bangalore, often called the Silicon Valley of India, is one of the fastest-growing cities in terms of lifestyle, employment, and urban infrastructure. With a massive population of working professionals, students, and expatriates, the demand for convenience-based services is at an all-time high. Among these, the Laundry Franchise business has emerged as one of the most profitable and scalable...

JiliCC is an online betting platform designed to provide users with a smooth, fast, and highly engaging experience. It stands out because of its strong connection with the gaming ecosystem developed by JILI Games, which brings a wide variety of interactive and entertaining options to players. The platform focuses on simplicity, speed, and visual appeal, making it suitable for both...