Comparative Analysis of GPU Compute Architectures for High-Performance Workloads
The increasing computational demands of artificial intelligence, high-performance computing (HPC), and real-time data processing have made GPU-accelerated infrastructure a necessity. Among available options, NVIDIA-based systems dominate due to their optimized parallel processing capabilities, Tensor Core acceleration, and mature software ecosystem. However, selecting the appropriate deployment model requires a detailed understanding of how different GPU infrastructures behave under production workloads.
Organizations exploring Dedicated NVIDIA GPU Server solutions typically compare three primary architectures: dedicated bare-metal GPU servers, virtualized GPU environments, and shared multi-tenant GPU clusters. Each model introduces distinct trade-offs in terms of performance isolation, resource utilization, and scalability.
Dedicated Bare-Metal GPU Architecture
Dedicated GPU servers provide exclusive access to physical hardware, ensuring complete isolation of compute resources. These systems are typically equipped with high-end NVIDIA GPUs such as A100, V100, or L40s, combined with multi-core CPUs and high-bandwidth memory subsystems.
A Dedicated NVIDIA GPU Server eliminates the overhead associated with virtualization layers, allowing direct communication between CPU and GPU via high-speed interconnects such as PCIe Gen4 or NVLink. This significantly improves data transfer rates and reduces latency in compute-intensive operations.
Research and infrastructure benchmarks indicate that dedicated GPU systems provide consistent throughput and deterministic performance, making them ideal for long-running workloads such as deep learning training and large-scale simulations.
Additionally, dedicated environments prevent resource contention, ensuring that workloads are not affected by other users, a common issue in shared infrastructures.
Virtualized GPU Environments
Virtualized GPU environments use hypervisors or container-based orchestration to partition GPU resources among multiple workloads. Technologies such as NVIDIA vGPU and Multi-Instance GPU (MIG) enable resource slicing, allowing multiple applications to share a single physical GPU.
Compared to a Dedicated NVIDIA GPU Server, virtualized environments offer better resource utilization. Instead of dedicating an entire GPU to a single workload, resources can be dynamically allocated based on demand.
However, virtualization introduces overhead in terms of:
-
Context switching between workloads
-
Memory bandwidth contention
-
PCIe bus sharing
Recent research highlights that GPU sharing can lead to performance degradation due to VRAM channel conflicts and bandwidth limitations, particularly in latency-sensitive applications.
While virtualization improves efficiency, it may not be suitable for workloads requiring strict performance guarantees.
Multi-Tenant Shared GPU Clusters
Shared GPU clusters are commonly used in cloud environments where multiple users access a pool of GPU resources. These systems prioritize cost efficiency and scalability over performance isolation.
In contrast to a Dedicated NVIDIA GPU Server, shared clusters rely on scheduling algorithms to allocate GPU resources dynamically. This allows providers to maximize utilization but introduces variability in performance.
Studies on multi-tenant GPU systems show that resource sharing can reduce costs but may also lead to underutilization or contention, depending on workload patterns.
The “noisy neighbor” effect is a significant concern in shared environments, where one workload can impact the performance of others due to competition for compute and memory resources.
Performance Consistency and Throughput Comparison
Performance consistency is a critical factor in GPU-intensive workloads. Dedicated systems provide stable throughput, as resources are not shared. This makes them ideal for training large neural networks, where consistent execution time is essential.
Virtualized and shared environments, on the other hand, may experience fluctuations due to resource contention and scheduling delays. While these models improve utilization, they often sacrifice predictability.
A Dedicated NVIDIA GPU Server ensures near-linear scaling for parallel workloads, as all GPU cores are available exclusively for a single task. This is particularly beneficial for distributed training and high-throughput inference systems.
Scalability and Resource Allocation
Scalability varies significantly across deployment models. Virtualized and shared environments offer dynamic scaling, allowing resources to be allocated based on real-time demand. This is advantageous for workloads with variable usage patterns.
Dedicated systems require manual scaling, which involves provisioning additional hardware. While this process is slower, it provides greater control over resource allocation and system configuration.
A hybrid approach, combining dedicated and virtualized resources, is often used to balance scalability and performance. In such setups, baseline workloads run on dedicated infrastructure, while peak demand is handled by virtualized resources.
Cost Efficiency and Utilization Trade-offs
Cost considerations differ across models. Shared GPU environments offer lower entry costs due to resource pooling, while virtualized systems provide a balance between cost and performance.
Dedicated systems, including a Dedicated NVIDIA GPU Server, involve higher upfront costs but deliver better cost efficiency for sustained workloads. Fixed pricing models eliminate variable costs associated with usage-based billing, making budgeting more predictable.
Research indicates that while shared environments improve utilization, they may lead to inefficiencies if workloads are not properly scheduled.
Dedicated systems, despite lower utilization in some cases, provide guaranteed performance, which is often more valuable for mission-critical applications.
Security and Data Isolation
Security is another key differentiator. Dedicated GPU servers provide complete isolation, ensuring that data and workloads remain within a controlled environment.
Virtualized and shared environments rely on software-level isolation, which may introduce potential vulnerabilities. While modern systems implement strong security measures, dedicated infrastructure remains the preferred choice for sensitive workloads.
A Dedicated NVIDIA GPU Server allows organizations to implement custom security policies, including network segmentation, encryption, and access control mechanisms.
Conclusion
Selecting the appropriate GPU infrastructure requires a comprehensive understanding of workload requirements, performance expectations, and cost constraints. Dedicated bare-metal servers provide unmatched performance and isolation, making them ideal for high-intensity workloads.
Virtualized environments improve resource utilization and flexibility but introduce performance overhead. Shared GPU clusters offer scalability and cost efficiency but may lack consistency.
A well-planned deployment strategy often involves combining these models to achieve optimal results. By evaluating the trade-offs between performance, scalability, and cost, organizations can design GPU infrastructures that support advanced computational workloads efficiently.
Categorias
Leia mais
Sudden backups can turn your day upside down, leaving sinks, tubs, and floor drains unusable and creating stress throughout your home. For fast, lasting results, consider scheduling hydro jetting in Huntsville, AL, a professional service designed to remove stubborn blockages, grease, sludge, hair, and mineral buildup from pipes. This ensures your plumbing flows smoothly again without delays,...
" According to the latest report published by Data Bridge Market Research, the Artificial Intelligence in Healthcare Market CAGR Value The universal Artificial Intelligence in Healthcare Market report has explained in-depth market insights about market size, latest trends, market threats and key drivers driving the market. This market research report also supports to secure...
Benefits of Using Certification Exam Preparation Material Certification exams help people grow in their careers. They help you get better jobs. They also help you earn more money. Many students want to pass the VCS-325 exam on the first attempt. This exam is offered by Veritas. However, exam preparation can feel difficult. There are many books to read and many topics to cover. This is why using...

The global air suspension market is witnessing substantial growth as vehicle manufacturers increasingly focus on enhancing ride comfort, vehicle stability, load-carrying capacity, and overall driving performance. Air suspension systems use compressed air instead of traditional steel springs to support vehicle weight and absorb road shocks. These systems are widely adopted across passenger...

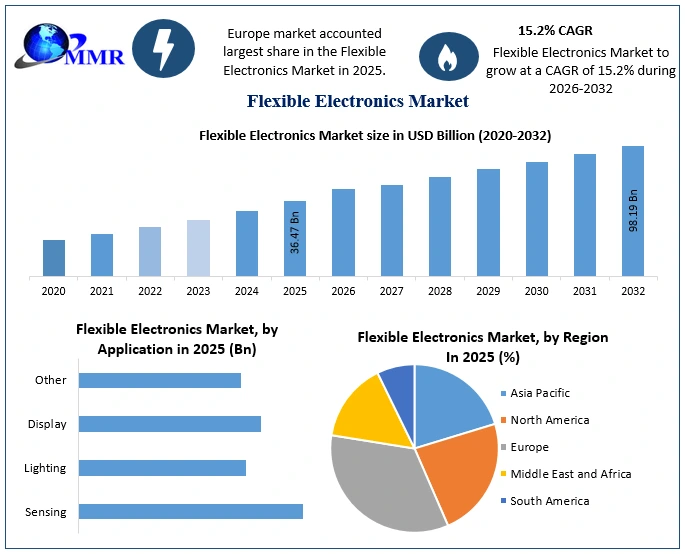
Flexible Electronics Market to Reach USD 87.65 Billion by 2032 at 8.9% CAGR | AI-Driven Smart Devices, Digital Transformation & Future of Electronics Revolution The global Flexible Electronics Market is entering a transformative growth cycle as AI-driven smart devices, connected ecosystems, next-generation display technologies, and IoT-enabled electronics redefine the future of...